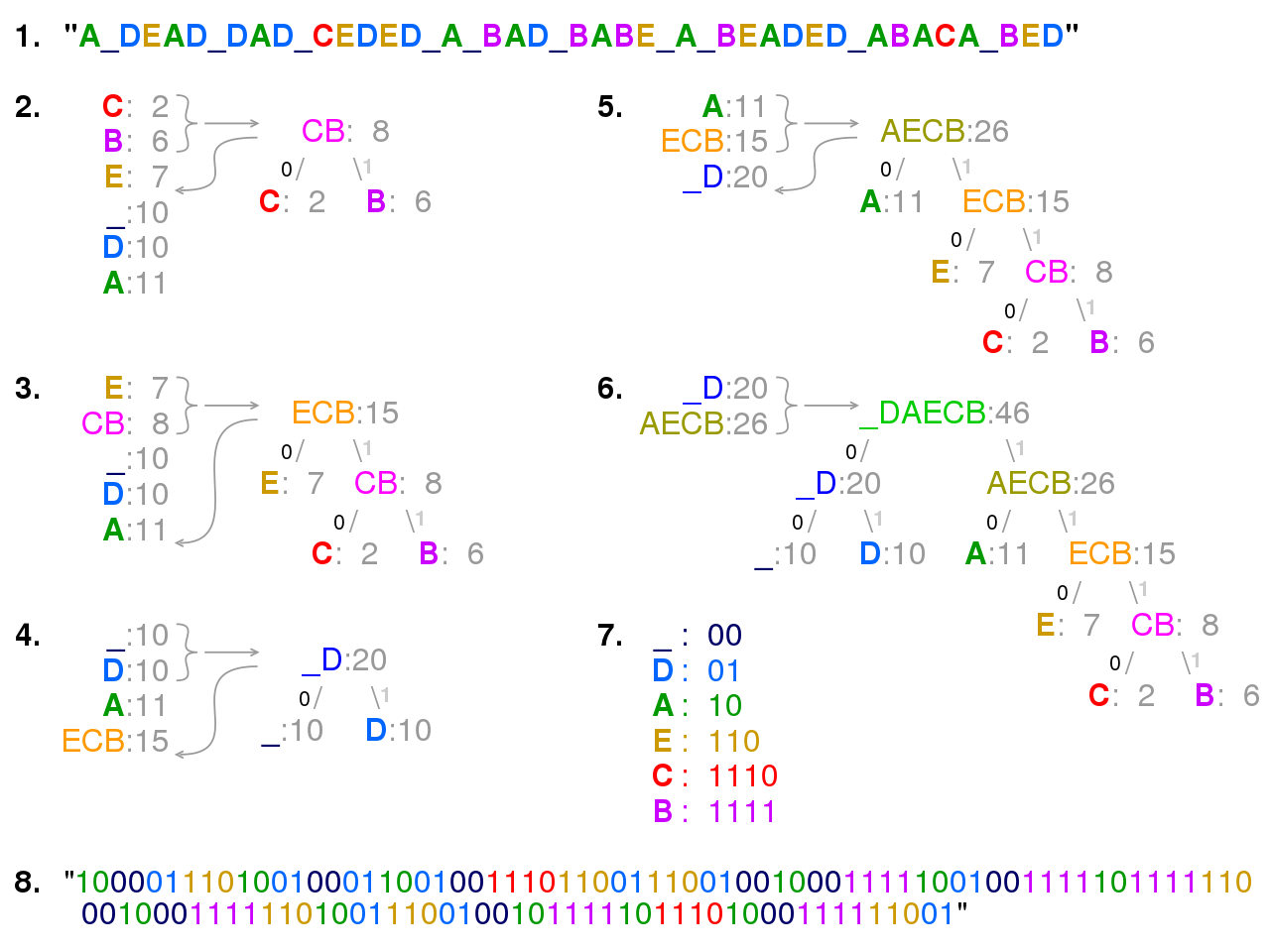
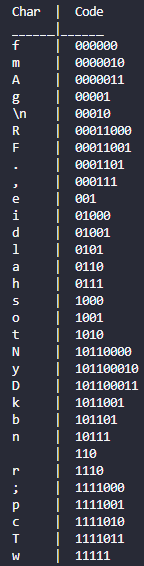
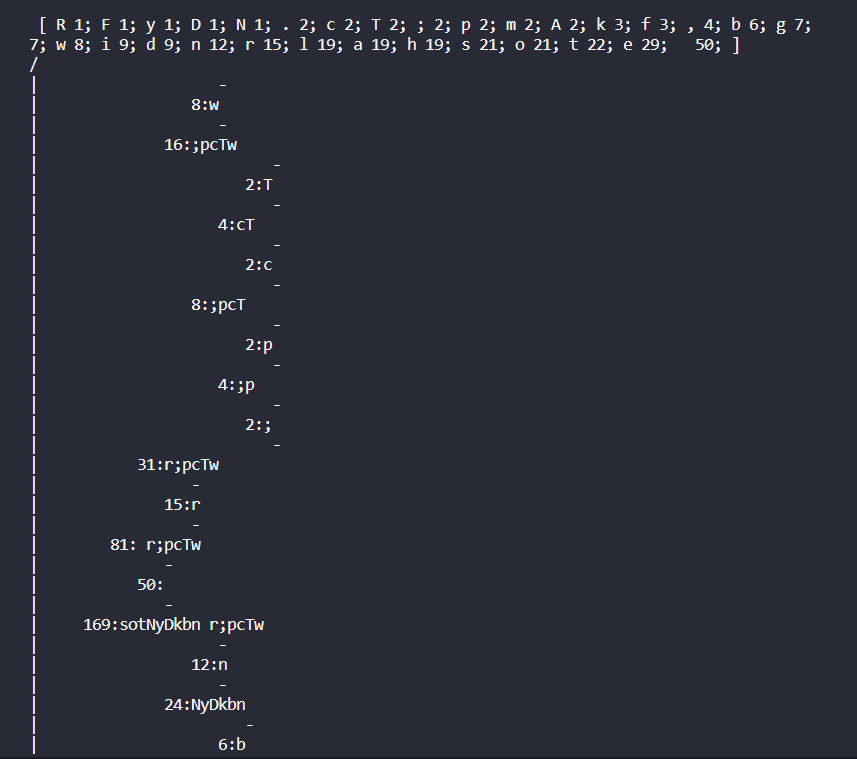
The figure above shows visual describing our implementation for our Huffman encoding script written in Golang. We initially
look at the frequency of all the characters in the file and order the characters from least to most frequent.
To store the frequency of the characters in each string, we use a doubly-linked list in which each element is
a cell which has the pointers next, previous, left, right, and parent. We also assign a character to each cell
and a value, which represents the number of times the character appears in our inputted string. Characters that appear
more frequently are assigned shorter codewords to maximize the compression of the encoded message.
One of the outputs of our script is a table matching characters to corresponding codewords.
The image above displays a list of the inputted characters and their frequencies, as well as a visualization of our Huffman encoding tree.